Data Storage Solutions And Apache Spark Quiz Answers

Apache Spark Online Quiz Questions And Answers Dataflair

Apache Spark Cluster Managers Yarn Mesos Standalone Dataflair

Db0 Wfim Qsc7m
50 Best Apache Spark Interview Questions Answers Updated

Conquering The Challenges Of Data Preparation For Predictive Maintenance In 2020 Data Supervised Machine Learning Predictions

Apache Spark 7 Important Aspects Of Big Data Apache Spak

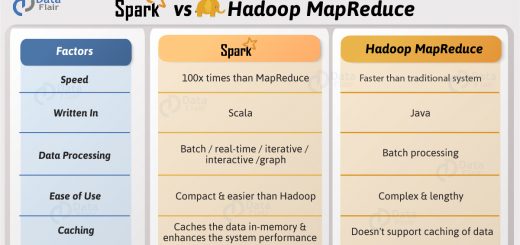
Hadoop is highly disk dependent whereas spark promotes caching and in memory data storage.
Data storage solutions and apache spark quiz answers. The following quiz contains the multiple choice questions related to the most common framework for bigdata i e. 05 graph analytics for big data. Therefore an applied knowledge of working with apache spark is a great asset and potential differentiator for a machine learning engineer. Apache spark is easy to use and flexible data processing framework.
2 explain dsstream with reference to apache spark. 04 machine learning with big data. Let s see what the correct answer is. The csv files could be in cloud storage or could be ingested into bigquery.
The correct answer is b use bigquery for the storage solution and cloud dataproc for the processing solution. Compare hadoop and spark. Sql databases anything that can be connected using jdbc driver. After learning apache spark try your hands on apache spark online quiz and get to know your learning so far.
This quiz will help you to revise the concepts of apache spark and will build up your confidence in spark. Apache spark is the best solution. Week 2 data storage apache spark rdds and sql. Update quiz 3 data exploration in knime and spark md.
Big data analytics and apache spark hive pig. 1 what is apache spark. In real life use case you usually have database or data repository frome where you access data from spark. Spark runs upto 100 times faster than.
Spark can access data that s in. Below are some multiple choice questions corresponding to them are the choice of answers. Spark can round on hadoop standalone or in the cloud. Added solution to hands on with splunk.
This part is actually very interesting. Spark is not a database so it cannot store data. Apache spark interview questions and answers 1. Read the apache spark online quiz question and click an appropriate answer following to the question.
Spark is capable of performing computations multiple times on the same dataset. Courses in this program. Okay cloud dataproc is correct because the question states you need to plan to reuse apache spark code. Apache spark is an open source framework that leverages cluster computing and distributed storage to process extremely large data sets in an efficient and cost effective manner.
Test your hands on apache spark fundamentals. Last year spark set a world record by completing a benchmark test involving sorting 100 terabytes of data in 23 minutes the previous world record of 71 minutes being held by hadoop. Merge pull request 2 from skvrahul patch 2. Here we begin to work on our understanding of different data storage solutions.
After covering the pros and cons of each we move into learning about apache spark focusing on scalability and parallel processing. Spark has proven very popular and is used by many large companies for huge multi petabyte data storage and analysis.

Scalable Machine Learning On Big Data Using Apache Spark Coursera
Chl5iwccfw0a4m
Top 100 Apache Spark Interview Questions And Answers Dataflair
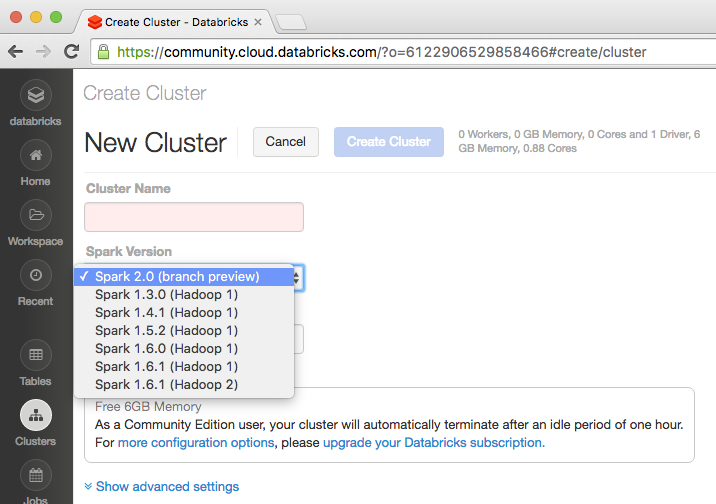
Spark 2 0 Preview Now On Databricks Community Edition Easier Faster Smarter

J B Kauqpafwcm
Https Www Knowledgehut Com Big Data Apache Spark And Scala Training

Announcing Preview Of Azure Hdinsight 3 6 With Apache Spark 2 1 Https Azure Microsoft Com De De Blog Announcing Preview Of Azure Hdinsight 3 6 With Apache Sp

The 12 Best Apache Spark Courses And Online Training For 2020

What Are The Differences Between Apache Spark Storm Samza Flink Beam Apex Quora Apache Spark Big Data Stream Processing
Github Tirthajyoti Spark With Python Fundamentals Of Spark With Python Using Pyspark Code Examples

Free Online Course Scalable Machine Learning On Big Data Using Apache Spark From Coursera Class Central

Sparkcamp Strata Ca Intro To Apache Spark With Hands On Tutorials

Stream Processing Changes Azure Cosmosdb Change Feed Apache Spark Apache Spark Stream Processing Apache

Is There Any Best Center To Learn Apache Spark In Bangalore Quora

Apache Spark Interview Questions With Answers Spark Interview Questions
Practical Apache Spark In 10 Minutes Part 3 Dataframes And Sql Data Science Central

Learning Spark 2ndedition Docx Apache Spark Apache Hadoop
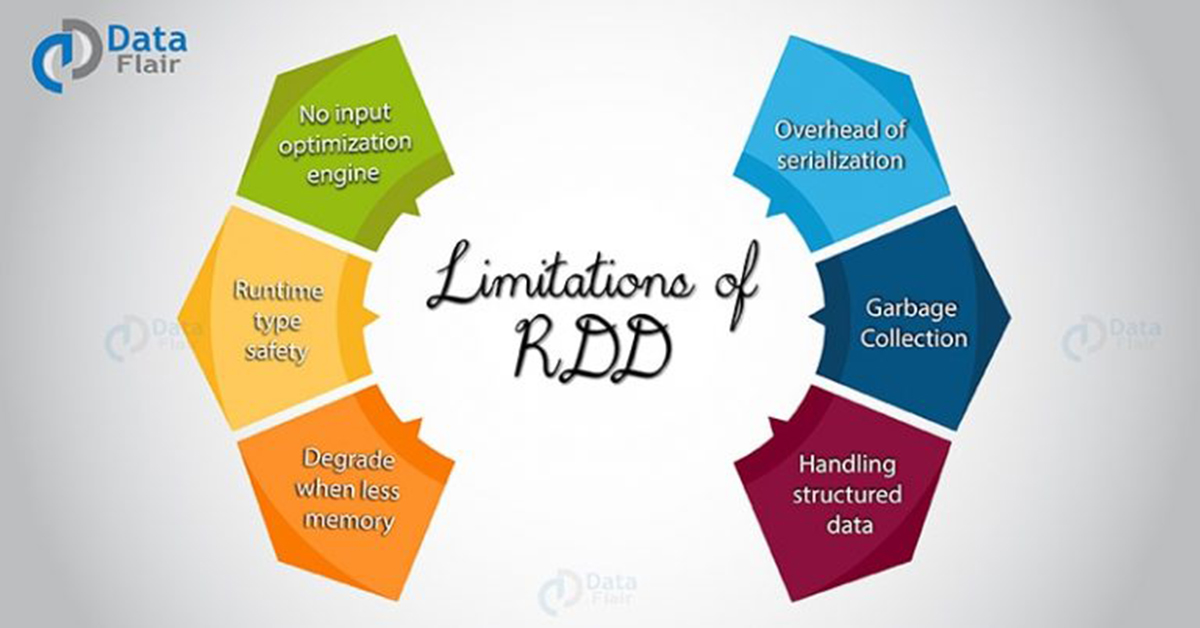
How To Overcome The Limitations Of Rdd In Apache Spark Dataflair
Https Encrypted Tbn0 Gstatic Com Images Q Tbn 3aand9gcsrzbtgccq Eisu1ixjhjednuxhs56eyqr Xqstasp8zcyazovd Usqp Cau
Which One Is Better Hadoop Or Spark Quora

Top 20 Apache Spark Interview Questions Answers 2018 Acadgild Blogs

Companies Using Sap Hana Career Growth Career Opportunities Business Analyst
9 Best Apache Spark Courses Training 2020

We Are Best Hadoop Training Institute In Bangalore Offering Hadoop Course In Bangalore With Advanced C Big Data Big Data Analytics Big Data Analytics Marketing
How To Train Your Neural Networks In Parallel With Keras And Apache Spark Mc Ai

Design Elements Aws Database Aws Architecture Diagram Diagram Architecture Diagram Design

Twitter Data Streaming Using Spark

Distributed Computing With Spark Sql Coursera

Pin On Microsoft Certifications Infographic
Spark Rdd Operations Transformation Action With Example Dataflair

Apache Spark Interview Questions And Answers Scala Sql Coding

Cloud Computing Applications Part 2 Big Data And Applications In The Cloud Coursera

Spark Sql Features Sql Reading Data Spark Program

Aix18utfrf4xzm

Spark With Scala Python Apache Storm Online Zarantech

Apache Spark In 24 Hours Sams Teach Yourself Ebook Aven Jeffrey Amazon In Kindle Store

Top 50 Hadoop Interview Questions For 2020 Edureka Blog

Programming Kotlin Download Pdf Book Program Book Addict What To Read

Apache Spark 24 Hours Pdf Apache Spark Apache Hadoop

Rvkckikbffbsom

1i 3xxtp7dq5qm

Fk4eboqrpd2zm

